publications
ordered in reversed chronological order.
For a longer list, please refer to the PI's Google Scholar page.
2024
-
 ×Optimizing Wind Turbine Surface Defect Detection: A Rotated Bounding Box ApproachImad Gohar, Abderrahim Halimi, Yew Weng Kean, and John See32nd European Conference on Signal Processing (to appear), 2024
×Optimizing Wind Turbine Surface Defect Detection: A Rotated Bounding Box ApproachImad Gohar, Abderrahim Halimi, Yew Weng Kean, and John See32nd European Conference on Signal Processing (to appear), 2024Detecting surface defects on Wind Turbine Blades (WTBs) from remotely sensed images is a crucial step toward automated visual inspection. Typical object detection algorithms use standard bounding boxes to locate defects on WTBs. However, Oriented Bounding Boxes (OBBs) have been shown in cases of satellite imagery, to provide more precise localization of object regions and actual orientation. Existing WTB datasets do not depict defects using OBBs and this causes the lack of useful orientational information. In this paper, we consider OBBs for WTB surface defect detection through two publicly available datasets, introducing new annotations to the community. Baselines were constructed on state-of-the-art rotated object detectors, demonstrating considerable promise and known gaps that can be addressed in the future. We present a comprehensive analysis of their performances including ablation study and discussions on the importance of angular disparity between OBBs.
-
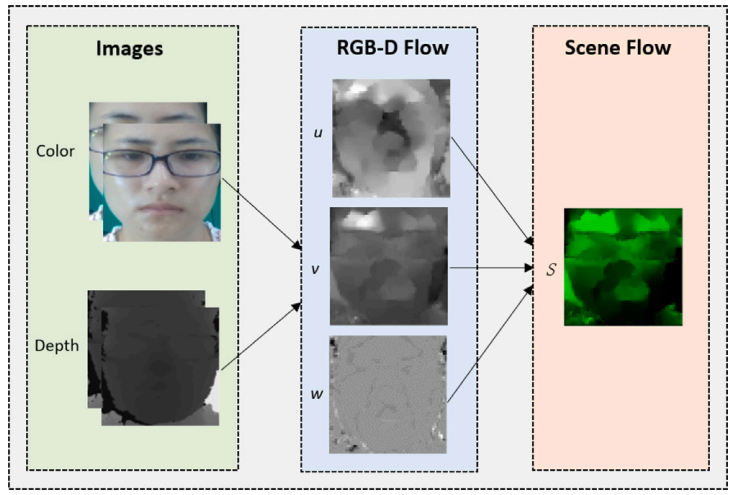 ×SFAMNet: A Scene Flow Attention-based Micro-expression NetworkGen-Bing Liong, Sze-Teng Liong, Chee Seng Chan, and John SeeNeurocomputing, 2024
×SFAMNet: A Scene Flow Attention-based Micro-expression NetworkGen-Bing Liong, Sze-Teng Liong, Chee Seng Chan, and John SeeNeurocomputing, 2024Tremendous progress has been made in facial Micro-Expression (ME) spotting and recognition; however, most works have focused on either spotting or recognition tasks on the 2D videos. Until recently, the estimation of the 3D motion field (a.k.a scene flow) for the ME has only become possible after the release of the multi-modal ME dataset. In this paper, we propose the first Scene Flow Attention-based Micro-expression Network, namely SFAMNet. It takes the scene flow computed using the RGB-D flow algorithm as the input and predicts the spotting confidence score and emotion labels. Specifically, SFAMNet is an attention-based end-to-end multi-stream multi-task network devised to spot and recognize the ME. Besides that, we present a data augmentation strategy to alleviate the small sample size problem during network learning. Extensive experiments are performed on three tasks: (i) ME spotting; (ii) ME recognition; and (iii) ME analysis on the multi-modal CAS(ME)^3 dataset. Empirical results indicate that depth is vital in capturing the ME information and the effectiveness of the proposed approach. Our source code is publicly available at https://github.com/genbing99/SFAMNet.
-
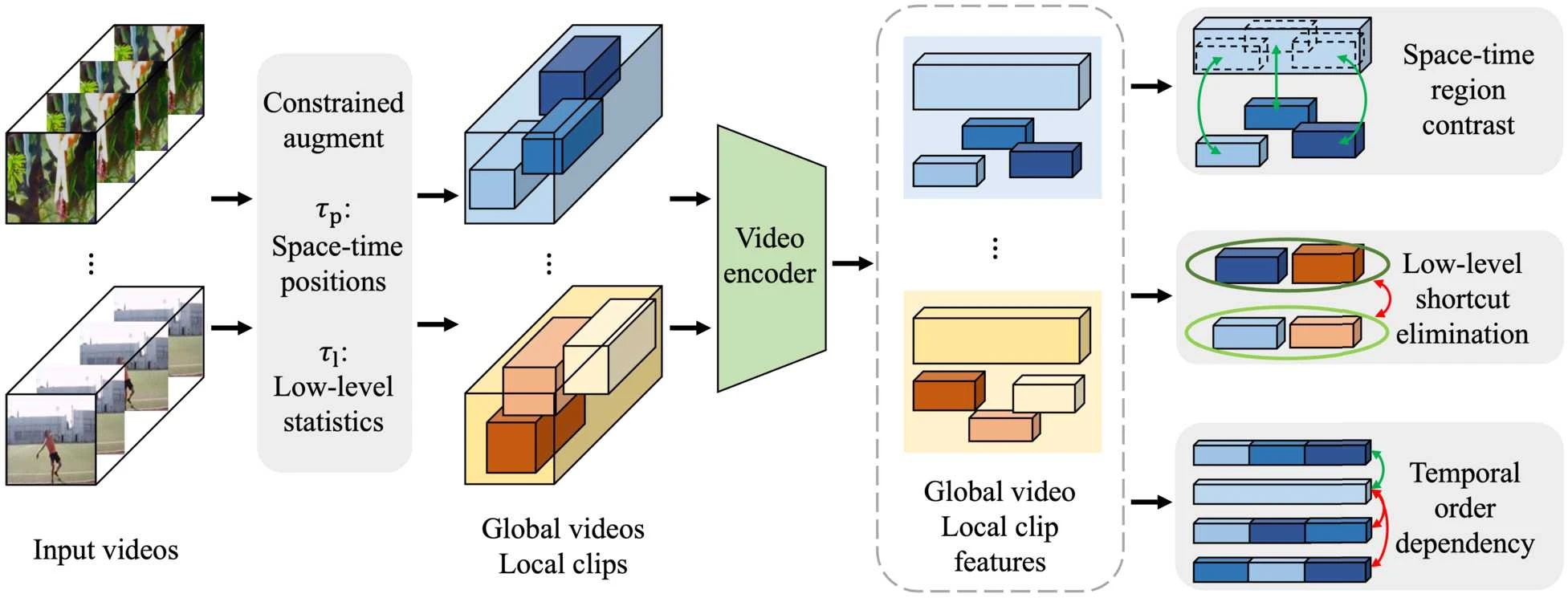 ×Controllable augmentations for video representation learningRui Qian, Weiyao Lin, John See, and Dian LiVisual Intelligence, 2024
×Controllable augmentations for video representation learningRui Qian, Weiyao Lin, John See, and Dian LiVisual Intelligence, 2024This paper focuses on self-supervised video representation learning. Most existing approaches follow the contrastive learning pipeline to construct positive and negative pairs by sampling different clips. However, this formulation tends to bias the static background and has difficulty establishing global temporal structures. The major reason is that the positive pairs, i.e., different clips sampled from the same video, have limited temporal receptive fields, and usually share similar backgrounds but differ in motions. To address these problems, we propose a framework to jointly utilize local clips and global videos to learn from detailed region-level correspondence as well as general long-term temporal relations. Based on a set of designed controllable augmentations, we implement accurate appearance and motion pattern alignment through soft spatio-temporal region contrast. Our formulation avoids the low-level redundancy shortcut with an adversarial mutual information minimization objective to improve the generalization ability. Moreover, we introduce local-global temporal order dependency to further bridge the gap between clip-level and video-level representations for robust temporal modeling. Extensive experiments demonstrate that our framework is superior on three video benchmarks in action recognition and video retrieval, and captures more accurate temporal dynamics.
-
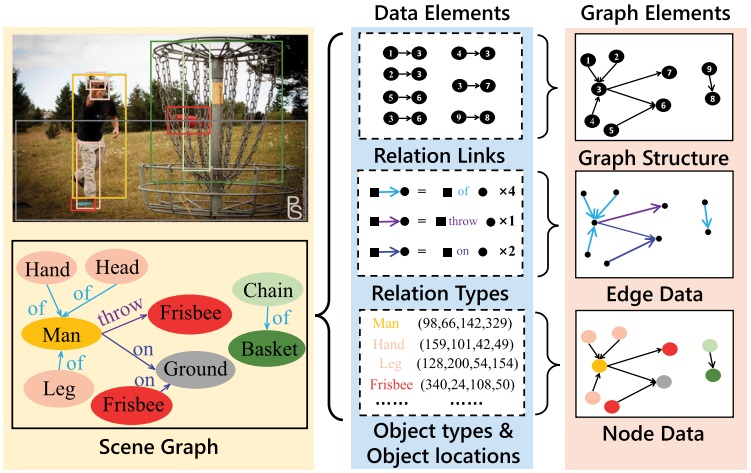 ×Scene Graph Lossless Compression with Adaptive Prediction for Objects and RelationsWeiyao Lin, Yufeng Zhang, Wenrui Dai, Huabin Liu, John See, and Hongkai XiongACM Transactions on Multimedia Computing, Communications and Applications, 2024
×Scene Graph Lossless Compression with Adaptive Prediction for Objects and RelationsWeiyao Lin, Yufeng Zhang, Wenrui Dai, Huabin Liu, John See, and Hongkai XiongACM Transactions on Multimedia Computing, Communications and Applications, 2024The scene graph is a novel data structure describing objects and their pairwise relationship within image scenes. As the size of scene graphs in vision and multimedia applications increases, the need for lossless storage and transmission of such data becomes more critical. However, the compression of scene graphs is less studied because of the complicated data structures involved and complex distributions. Existing solutions usually involve general-purpose compressors or graph structure compression methods, which are weak at reducing the redundancy in scene graph data. This article introduces a novel lossless compression framework with adaptive predictors for the joint compression of objects and relations in scene graph data. The proposed framework comprises a unified prior extractor and specialized element predictors to adapt to different data elements. Furthermore, to exploit the context information within and between graph elements, Graph Context Convolution is proposed to support different graph context modeling schemes for different graph elements. Finally, an overarching framework incorporates the learned distribution model to predict numerical data under complicated conditional constraints. Experiments conducted on labeled or generated scene graphs demonstrate the effectiveness of the proposed framework for scene graph lossless compression.
-
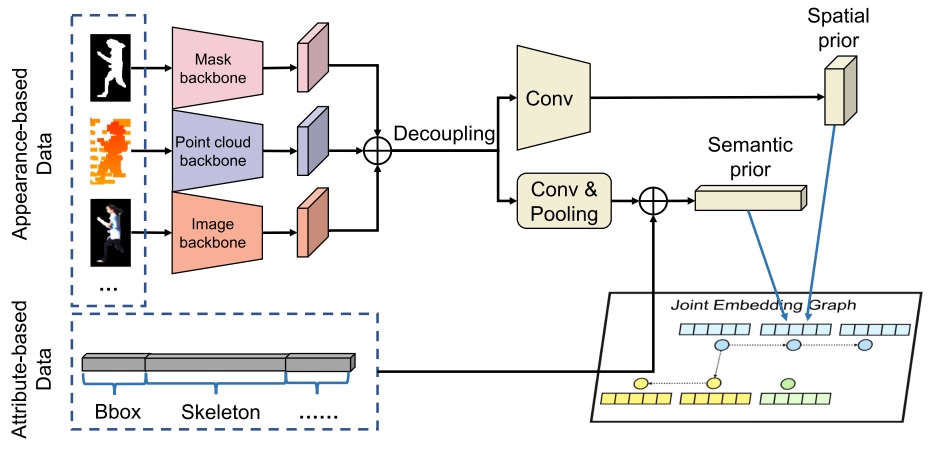 ×A Unified Framework for Jointly Compressing Visual and Semantic DataShizhan Liu, Weiyao Lin, Yihang Chen, Yufeng Zhang, Wenrui Dai, John See, and Hong-Kai XiongACM Transactions on Multimedia Computing, Communications and Applications, 2024
×A Unified Framework for Jointly Compressing Visual and Semantic DataShizhan Liu, Weiyao Lin, Yihang Chen, Yufeng Zhang, Wenrui Dai, John See, and Hong-Kai XiongACM Transactions on Multimedia Computing, Communications and Applications, 2024The rapid advancement of multimedia and imaging technologies has resulted in increasingly diverse visual and semantic data. A large range of applications such as remote-assisted driving requires the amalgamated storage and transmission of various visual and semantic data. However, existing works suffer from the limitation of insufficiently exploiting the redundancy between different types of data. In this article, we propose a unified framework to jointly compress a diverse spectrum of visual and semantic data, including images, point clouds, segmentation maps, object attributes, and relations. We develop a unifying process that embeds the representations of these data into a joint embedding graph according to their categories, which enables flexible handling of joint compression tasks for various visual and semantic data. To fully leverage the redundancy between different data types, we further introduce an embedding-based adaptive joint encoding process and a Semantic Adaptation Module to efficiently encode diverse data based on the learned embeddings in the joint embedding graph. Experiments on the Cityscapes, MSCOCO, and KITTI datasets demonstrate the superiority of our framework, highlighting promising steps toward scalable multimedia processing.
2023
-
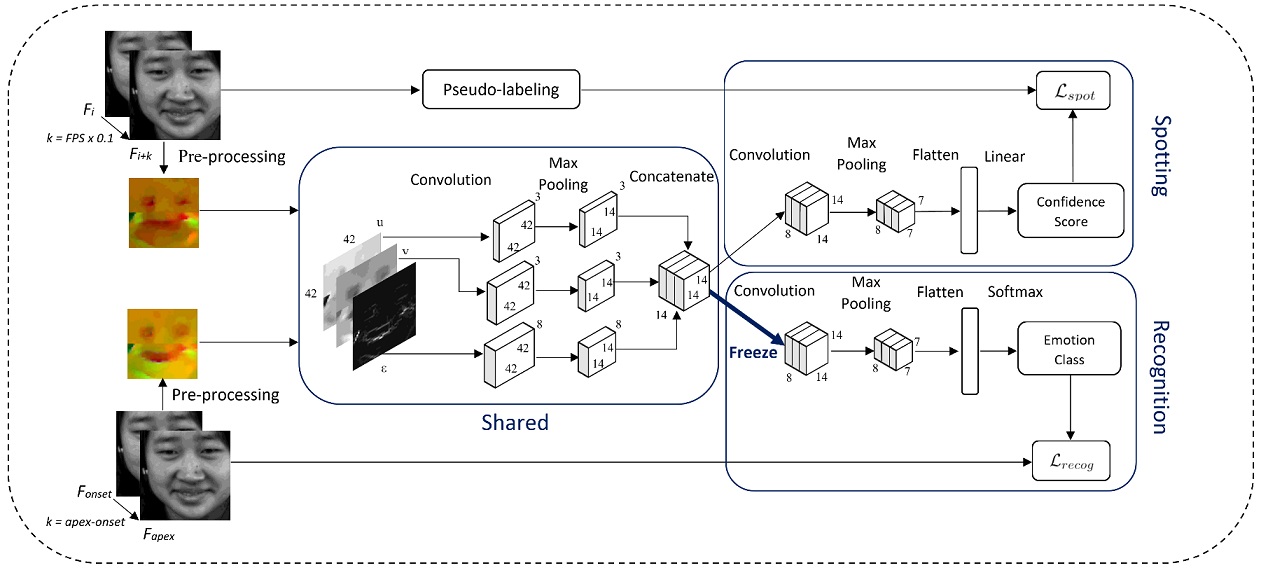 ×Spot-then-recognize: A micro-expression analysis network for seamless evaluation of long videosGen-Bing Liong, John See, and Chee-Seng ChanSignal Processing: Image Communication, 2023
×Spot-then-recognize: A micro-expression analysis network for seamless evaluation of long videosGen-Bing Liong, John See, and Chee-Seng ChanSignal Processing: Image Communication, 2023Facial Micro-Expressions (MEs) reveal a person’s hidden emotions in high stake situations within a fraction of a second and at a low intensity. The broad range of potential real-world applications that can be applied has drawn considerable attention from researchers in recent years. However, both spotting and recognition tasks are often treated separately. In this paper, we present Micro-Expression Analysis Network (MEAN), a shallow multi-stream multi-output network architecture comprising of task-specific (spotting and recognition) networks that is designed to effectively learn a meaningful representation from both ME class labels and location-wise pseudo-labels. Notably, this is the first known work that addresses ME analysis on long videos using a deep learning approach, whereby ME spotting and recognition are performed sequentially in a two-step procedure: first spotting the ME intervals using the spotting network, and proceeding to predict their emotion classes using the recognition network. We report extensive benchmark results on the ME analysis task on both short video datasets (CASME II, SMIC-E-HS, SMIC-E-VIS, and SMIC-E-NIR), and long video datasets (CAS(ME)2 and SAMMLV); the latter in particular demonstrates the capability of the proposed approach under unconstrained settings. Besides the standard measures, we promote the usage of fairer metrics in evaluating the performance of a complete ME analysis system. We also provide visual explanations of where the network is “looking” and showcasing the effectiveness of inductive transfer applied during network training. An analysis is performed on the in-the-wild dataset (MEVIEW) to open up further research into real-world scenarios.
-
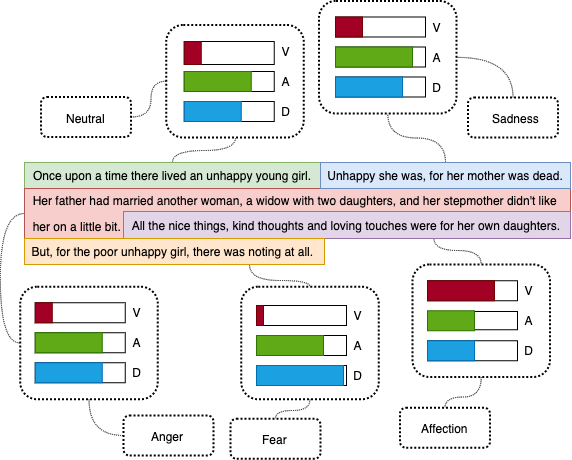 ×EmoStory: Emotion Prediction and Mapping in Narrative StoriesSeng Wei Too, John See, Albert Quek, and Hui Ngo GohInternational Journal on Informatics Visualization, 2023
×EmoStory: Emotion Prediction and Mapping in Narrative StoriesSeng Wei Too, John See, Albert Quek, and Hui Ngo GohInternational Journal on Informatics Visualization, 2023A well-designed story is built upon a sequence of plots and events. Each event has its purpose in piquing the audience’s interest in the plot; thus, understanding the flow of emotions within the story is vital to its success. A story is usually built up through dramatic changes in emotion and mood to create resonance with the audience. The lack of research in this understudied field warrants exploring several aspects of the emotional analysis of stories. In this paper, we propose an encoder-decoder framework to perform sentence-level emotion recognition of narrative stories on both dimensional and categorical aspects, achieving MAE=0.0846 and 54% accuracy (8-class), respectively, on the EmoTales dataset and a reasonably good level of generalization to an untrained dataset. The first use of attention and multi-head attention mechanisms for emotion representation mapping (ERM) yields state-of-the-art performance in certain settings. We further present the preliminary idea of EmoStory, a concept that seamlessly predicts both dimensional and categorical space in an efficient manner, made possible with ERM. This methodology is useful in only one of the two aspects is available. In the future, these techniques could be extended to model the personality or emotional state of characters in stories, which could benefit the affective assessment of experiences and the creation of emotive avatars and virtual worlds.
-
 ×Doing More With Moiré Pattern Detection in Digital PhotosCong Yang, Zhenyu Yang, Yan Ke, Tao Chen, Marcin Grzegorzek, and John SeeIEEE Transactions on Image Processing, 2023
×Doing More With Moiré Pattern Detection in Digital PhotosCong Yang, Zhenyu Yang, Yan Ke, Tao Chen, Marcin Grzegorzek, and John SeeIEEE Transactions on Image Processing, 2023Detecting moiré patterns in digital photographs is meaningful as it provides priors towards image quality evaluation and demoiréing tasks. In this paper, we present a simple yet efficient framework to extract moiré edge maps from images with moiré patterns. The framework includes a strategy for training triplet (natural image, moiré layer, and their synthetic mixture) generation, and a Moiré Pattern Detection Neural Network (MoireDet) for moiré edge map estimation. This strategy ensures consistent pixel-level alignments during training, accommodating characteristics of a diverse set of camera-captured screen images and real-world moiré patterns from natural images. The design of three encoders in MoireDet exploits both high-level contextual and low-level structural features of various moiré patterns. Through comprehensive experiments, we demonstrate the advantages of MoireDet: better identification precision of moiré images on two datasets, and a marked improvement over state-of-the-art demoiréing methods.
-
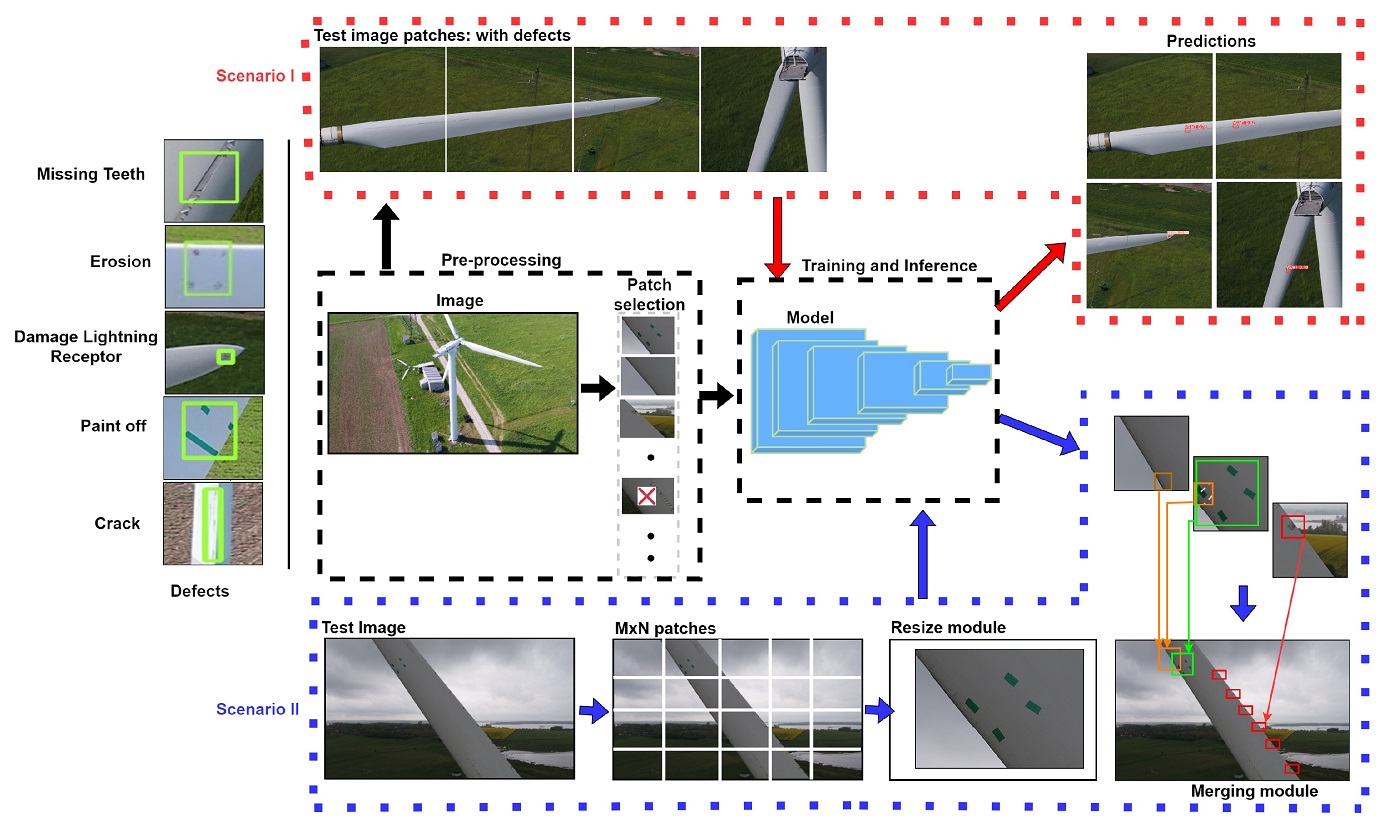 ×Slice-Aided Defect Detection in Ultra High-Resolution Wind Turbine Blade ImagesImad Gohar, Abderrahim Halimi, John See, Weng Kean Yew, and Cong YangMachines, 2023
×Slice-Aided Defect Detection in Ultra High-Resolution Wind Turbine Blade ImagesImad Gohar, Abderrahim Halimi, John See, Weng Kean Yew, and Cong YangMachines, 2023The processing of aerial images taken by drones is a challenging task due to their high resolution and the presence of small objects. The scale of the objects varies diversely depending on the position of the drone, which can result in loss of information or increased difficulty in detecting small objects. To address this issue, images are either randomly cropped or divided into small patches before training and inference. This paper proposes a defect detection framework that harnesses the advantages of slice-aided inference for small and medium-size damage on the surface of wind turbine blades. This framework enables the comparison of different slicing strategies, including a conventional patch division strategy and a more recent slice-aided hyper-inference, on several state-of-the-art deep neural network baselines for the detection of surface defects in wind turbine blade images. Our experiments provide extensive empirical results, highlighting the benefits of using the slice-aided strategy and the significant improvements made by these networks on an ultra high-resolution drone image dataset.
-
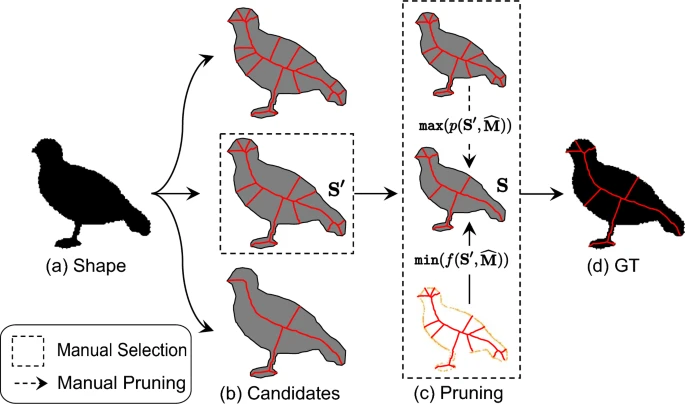 ×Skeleton Ground Truth Extraction: Methodology, Annotation Tool and BenchmarksCong Yang, Bipin Indurkhya, John See, Bo Gao, Yan Ke, Zeyd Boukhers, Zhenyu Yang, and Marcin GrzegorzekInternational Journal of Computer Vision, 2023
×Skeleton Ground Truth Extraction: Methodology, Annotation Tool and BenchmarksCong Yang, Bipin Indurkhya, John See, Bo Gao, Yan Ke, Zeyd Boukhers, Zhenyu Yang, and Marcin GrzegorzekInternational Journal of Computer Vision, 2023Skeleton Ground Truth (GT) is critical to the success of supervised skeleton extraction methods, especially with the popularity of deep learning techniques. Furthermore, we see skeleton GTs used not only for training skeleton detectors with Convolutional Neural Networks (CNN), but also for evaluating skeleton-related pruning and matching algorithms. However, most existing shape and image datasets suffer from the lack of skeleton GT and inconsistency of GT standards. As a result, it is difficult to evaluate and reproduce CNN-based skeleton detectors and algorithms on a fair basis. In this paper, we present a heuristic strategy for object skeleton GT extraction in binary shapes and natural images. Our strategy is built on an extended theory of diagnosticity hypothesis, which enables encoding human-in-the-loop GT extraction based on clues from the target’s context, simplicity, and completeness. Using this strategy, we developed a tool, SkeView, to generate skeleton GT of 17 existing shape and image datasets. The GTs are then structurally evaluated with representative methods to build viable baselines for fair comparisons. Experiments demonstrate that GTs generated by our strategy yield promising quality with respect to standard consistency, and also provide a balance between simplicity and completeness.
-
 ×ERNet: An Efficient and Reliable Human-Object Interaction Detection NetworkJunYi Lim, Vishnu Monn Baskaran, Joanne Mun-Yee Lim, KokSheik Wong, John See, and Massimo TistarelliIEEE Transactions on Image Processing, 2023
×ERNet: An Efficient and Reliable Human-Object Interaction Detection NetworkJunYi Lim, Vishnu Monn Baskaran, Joanne Mun-Yee Lim, KokSheik Wong, John See, and Massimo TistarelliIEEE Transactions on Image Processing, 2023Human-Object Interaction (HOI) detection recognizes how persons interact with objects, which is advantageous in autonomous systems such as self-driving vehicles and collaborative robots. However, current HOI detectors are often plagued by model inefficiency and unreliability when making a prediction, which consequently limits its potential for real-world scenarios. In this paper, we address these challenges by proposing ERNet, an end-to-end trainable convolutional-transformer network for HOI detection. The proposed model employs an efficient multi-scale deformable attention to effectively capture vital HOI features. We also put forward a novel detection attention module to adaptively generate semantically rich instance and interaction tokens. These tokens undergo pre-emptive detections to produce initial region and vector proposals that also serve as queries which enhances the feature refinement process in the transformer decoders. Several impactful enhancements are also applied to improve the HOI representation learning. Additionally, we utilize a predictive uncertainty estimation framework in the instance and interaction classification heads to quantify the uncertainty behind each prediction. By doing so, we can accurately and reliably predict HOIs even under challenging scenarios. Experiment results on the HICO-Det, V-COCO, and HOI-A datasets demonstrate that the proposed model achieves state-of-the-art performance in detection accuracy and training efficiency. Codes are publicly available at https://github.com/Monash-CyPhi-AI-Research-Lab/ernet.
-
 ×MEGC2023: ACM Multimedia 2023 ME Grand ChallengeAdrian K Davison, Jingting Li, Moi Hoon Yap, John See, Wen-Huang Cheng, Xiaobai Li, Xiaopeng Hong, and Su-Jing WangProceedings of the 31st ACM International Conference on Multimedia, 2023
×MEGC2023: ACM Multimedia 2023 ME Grand ChallengeAdrian K Davison, Jingting Li, Moi Hoon Yap, John See, Wen-Huang Cheng, Xiaobai Li, Xiaopeng Hong, and Su-Jing WangProceedings of the 31st ACM International Conference on Multimedia, 2023Facial micro-expressions (MEs) are involuntary movements of the face that occur spontaneously when a person experiences an emotion but attempts to suppress or repress the facial expression, typically found in a high-stakes environment. Unfortunately, the small sample problem severely limits the automation of ME analysis. Furthermore, due to the weak and transient nature of MEs, it is difficult for models to distinguish it from other types of facial actions. Therefore, ME in long videos is a challenging task, and the current performance cannot meet the practical application requirements. Addressing these issues, this challenge focuses on ME and the macro-expression (MaE) spotting task. This year, in order to evaluate algorithms’ performance more fairly, based on CAS(ME)2, SAMM Long Videos, SMIC-E-long, CAS(ME)3 and 4DME, we build an unseen cross-cultural long-video test set. All participating algorithms are required to run on this test set and submit their results on a leaderboard with a baseline result.
-
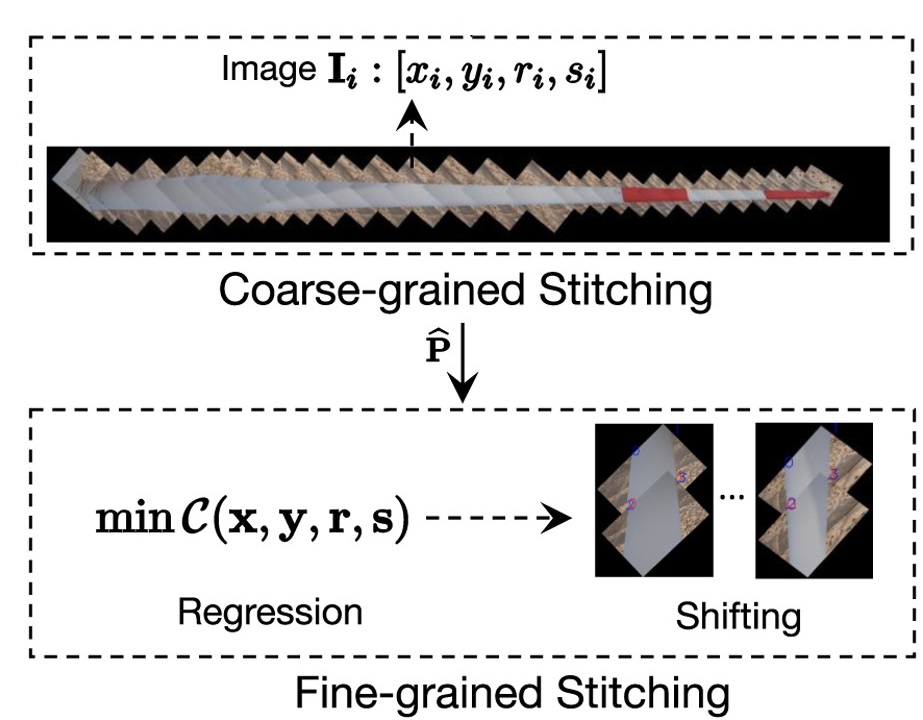 ×Towards accurate image stitching for drone-based wind turbine blade inspectionCong Yang, Xun Liu, Hua Zhou, Yan Ke, and John SeeRenewable Energy, 2023
×Towards accurate image stitching for drone-based wind turbine blade inspectionCong Yang, Xun Liu, Hua Zhou, Yan Ke, and John SeeRenewable Energy, 2023Accurate image stitching is crucial to wind turbine blade visualization and defect analysis. It is inevitable that drone-captured images for blade inspection are high resolution and heavily overlapped. This also necessitates the stitching-based deduplication process on detected defects. However, the stitching task suffers from texture-poor blade surfaces, unstable drone pose (especially off-shore), and the lack of public blade datasets that cater to real-world challenges. In this paper, we present a simple yet efficient algorithm for robust and accurate blade image stitching. To promote further research, we also introduce a new dataset, Blade30, which contains 1,302 real drone-captured images covering 30 full blades captured under various conditions (both on- and off-shore), accompanied by a rich set of annotations such as defects and contaminations, etc. The proposed stitching algorithm generates the initial blade panorama based on blade edges and drone-blade distances at the coarse-grained level, followed by fine-grained adjustments optimized by regression-based texture and shape losses. Our method also fully utilizes the properties of blade images and prior information of the drone. Experiments report promising accuracy in blade stitching and defect deduplication tasks in the vision-based wind turbine blade inspection scenario, surpassing the performance of existing methods.
-
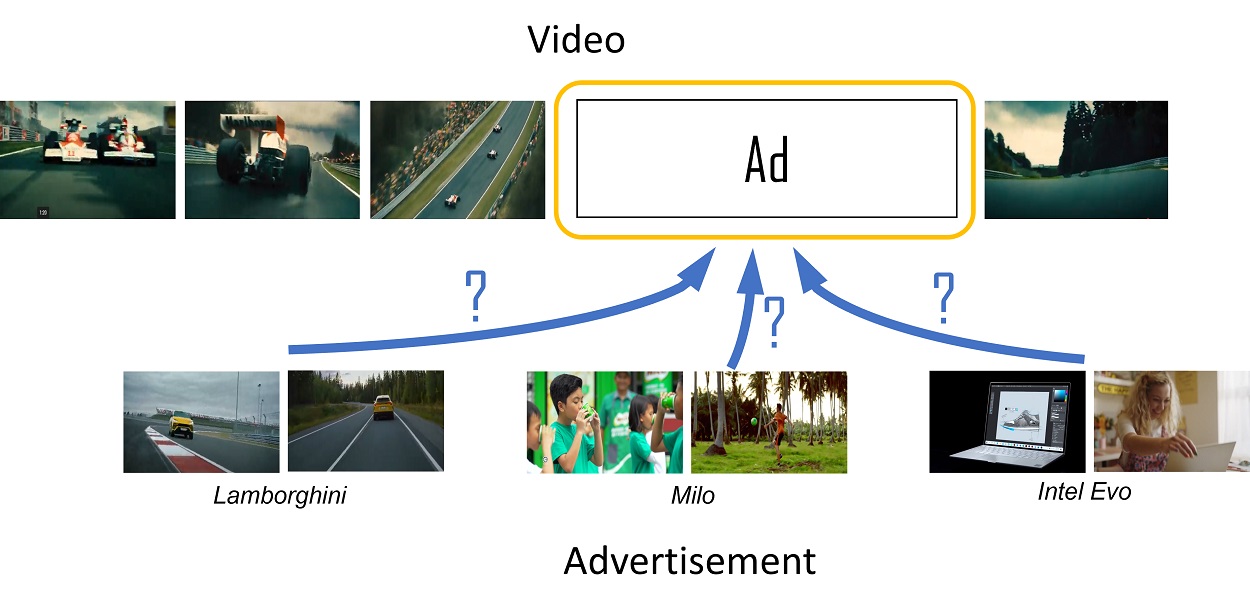 ×What Modality Matters? Exploiting Highly Relevant Features for Video Advertisement InsertionOnn Keat Chong, Hui-Ngo Goh, and John SeeIEEE International Conference on Image Processing (ICIP), 2023
×What Modality Matters? Exploiting Highly Relevant Features for Video Advertisement InsertionOnn Keat Chong, Hui-Ngo Goh, and John SeeIEEE International Conference on Image Processing (ICIP), 2023Video advertising is a thriving industry that has recently turned its attention to the use of intelligent algorithms for automating tasks. In advertisement insertion, the integration of contextual relevance is essential in influencing the viewer’s experience. Despite the wide spectrum of audio-visual semantic modalities available, there is a lack of research that analyzes their individual and complementary strengths in a systematic manner. In this paper, we propose an ad-insertion framework that maximizes the contextual relevance between advertisement and content video by employing high-level multi-modal semantic features. Prediction vectors are derived via clip-level and image-level extractors, which are then matched accordingly to yield relevance scores. We also established a new user study methodology that produces gold standard annotations based on multiple expert selections. By comprehensive human-centered approaches and analysis, we demonstrate that automatic ad-insertion can be improved by exploiting effective combinations of semantic modalities.
-
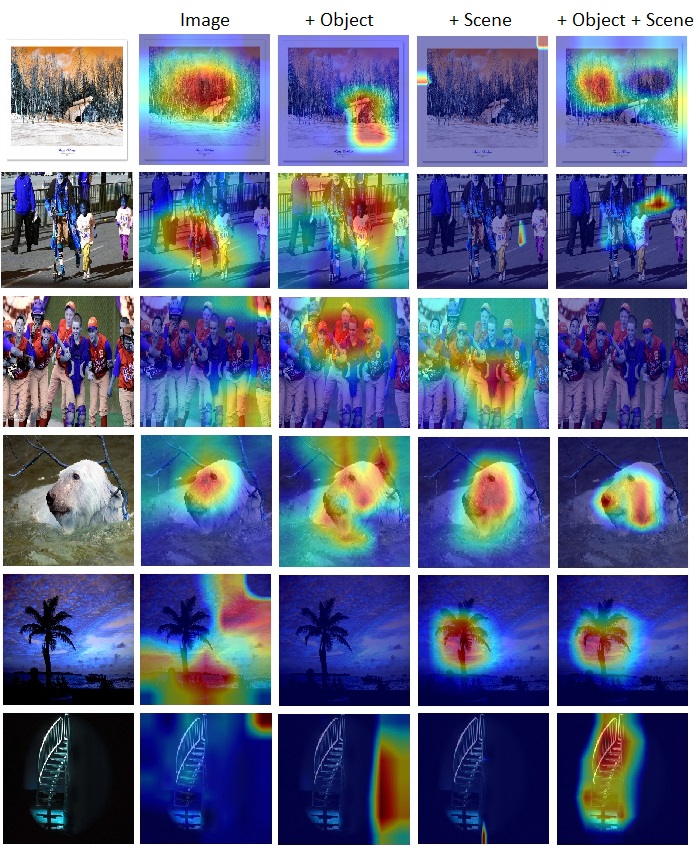 ×Context-Aware Multi-Stream Networks for Dimensional Emotion Prediction in ImagesSidharrth Nagappan, Jia Qi Tan, Lai-Kuan Wong, and John SeeIEEE International Conference on Image Processing (ICIP), 2023
×Context-Aware Multi-Stream Networks for Dimensional Emotion Prediction in ImagesSidharrth Nagappan, Jia Qi Tan, Lai-Kuan Wong, and John SeeIEEE International Conference on Image Processing (ICIP), 2023Teaching machines to comprehend the nuances of emotion from photographs is a particularly challenging task. Emotion perception— naturally a subjective problem, is often simplified for computational purposes into categorical states or valence-arousal dimensional space, the latter being a lesser-explored problem in the literature. This paper proposes a multi-stream context-aware neural network model for dimensional emotion prediction in images. Models were trained using a set of object and scene data along with deep features for valence, arousal, and dominance estimation. Experimental evaluation on a large-scale image emotion dataset demonstrates the viability of our proposed approach. Our analysis postulates that the understanding of the depicted object in an image is vital for successful predictions whilst relying on scene information can lead to somewhat confounding effects.
2022
-
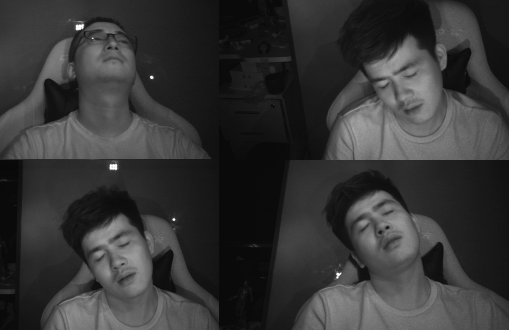 ×FatigueView: A Multi-Camera Video Dataset for Vision-Based Drowsiness DetectionCong Yang, Zhenyu Yang, Weiyu Li, and John SeeIEEE Transactions on Intelligent Transportation Systems, 2022
×FatigueView: A Multi-Camera Video Dataset for Vision-Based Drowsiness DetectionCong Yang, Zhenyu Yang, Weiyu Li, and John SeeIEEE Transactions on Intelligent Transportation Systems, 2022Although vision-based drowsiness detection approaches have achieved great success on empirically organized datasets, it remains far from being satisfactory for deployment in practice. One crucial issue lies in the scarcity and lack of datasets that represent the actual challenges in real-world applications, e.g. tremendous variation and aggregation of visual signs, challenges brought on by different camera positions and camera types. To promote research in this field, we introduce a new large-scale dataset, FatigueView, that is collected by both RGB and infrared (IR) cameras from five different positions. It contains real sleepy driving videos and various visual signs of drowsiness from subtle to obvious, e.g. with 17,403 different yawning sets totaling more than 124 million frames, far more than recent actively used datasets. We also provide hierarchical annotations for each video, ranging from spatial face landmarks and visual signs to temporal drowsiness locations and levels to meet different research requirements. We structurally evaluate representative methods to build viable baselines. With FatigueView, we would like to encourage the community to adapt computer vision models to address practical real-world concerns, particularly the challenges posed by this dataset.
-
 ×Badmintondb: A badminton dataset for player-specific match analysis and predictionKar-Weng Ban, John See, Junaidi Abdullah, and Yuen Peng LohProceedings of the 5th International ACM Workshop on Multimedia Content Analysis in Sports, 2022
×Badmintondb: A badminton dataset for player-specific match analysis and predictionKar-Weng Ban, John See, Junaidi Abdullah, and Yuen Peng LohProceedings of the 5th International ACM Workshop on Multimedia Content Analysis in Sports, 2022This paper introduces BadmintonDB, a new badminton dataset for training models for player-specific match analysis and prediction tasks, which are interesting challenges. The dataset features rally, strokes, and outcome annotations of 9 real-world badminton matches between two top players. We discussed our methodologies and processes behind selecting and annotating the matches. We also proposed player-independent and player-dependent Naive Bayes baselines for rally outcome prediction. The paper concludes with the analysis performed on the experiments to study the effects of player-dependent model on the prediction performances. We released our dataset at https://github.com/kwban/badminton-db.
-
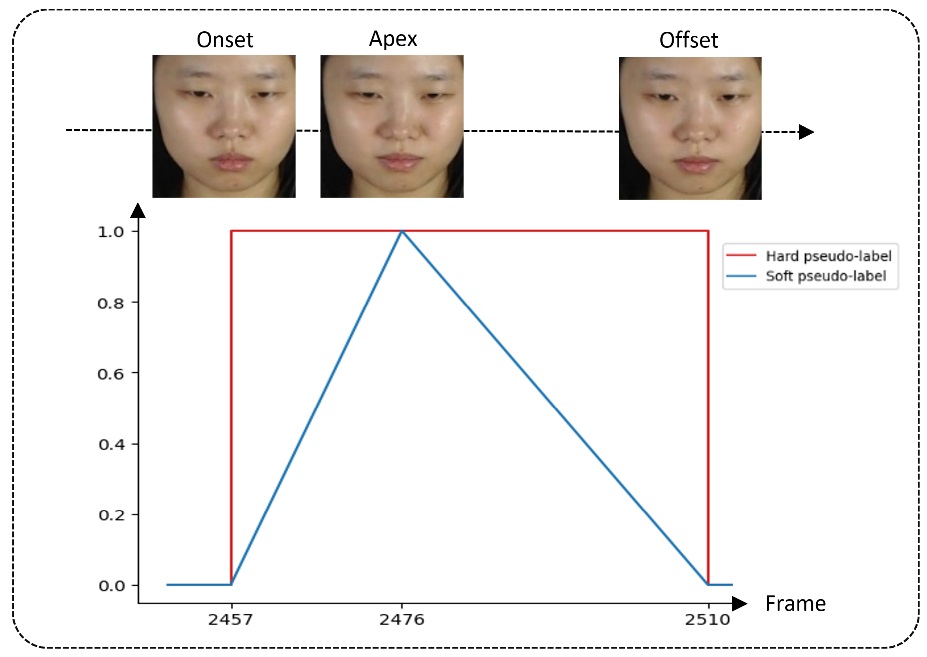 ×Mtsn: A multi-temporal stream network for spotting facial macro-and micro-expression with hard and soft pseudo-labelsGen Bing Liong, Sze-Teng Liong, John See, and Chee-Seng ChanProceedings of the 2nd Workshop on Facial Micro-Expression: Advanced Techniques for Multi-Modal Facial Expression Analysis, 2022
×Mtsn: A multi-temporal stream network for spotting facial macro-and micro-expression with hard and soft pseudo-labelsGen Bing Liong, Sze-Teng Liong, John See, and Chee-Seng ChanProceedings of the 2nd Workshop on Facial Micro-Expression: Advanced Techniques for Multi-Modal Facial Expression Analysis, 2022This paper considers the challenge of spotting facial macro- and micro-expression from long videos. We propose the multi-temporal stream network (MTSN) model that takes two distinct inputs by considering the different temporal information in the facial movement. We also introduce a hard and soft pseudo-labeling technique to enable the network to distinguish expression frames from non-expression frames via the learning of salient features in the expression peak frame. Consequently, we demonstrate how a single output from the MTSN model can be post-processed to predict both macro- and micro-expression intervals. Our results outperform the MEGC 2022 baseline method significantly by achieving an overall F1-score of 0.2586 and also did remarkably well on the MEGC 2021 benchmark with an overall F1-score of 0.3620 and 0.2867 on CAS(ME)2 and SAMM Long Videos, respectively.
-
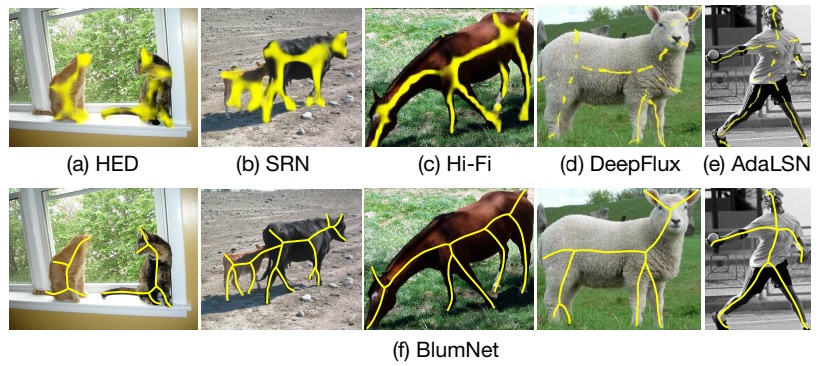 ×BlumNet: Graph component detection for object skeleton extractionYulu Zhang, Liang Sang, Marcin Grzegorzek, John See, and Cong YangProceedings of the 30th ACM International Conference on Multimedia, 2022
×BlumNet: Graph component detection for object skeleton extractionYulu Zhang, Liang Sang, Marcin Grzegorzek, John See, and Cong YangProceedings of the 30th ACM International Conference on Multimedia, 2022In this paper, we present a simple yet efficient framework, BlumNet, for extracting object skeletons in natural images and binary shapes. With the need for highly reliable skeletons in various multimedia applications, the proposed BlumNet is distinguished in three aspects: (1) The inception of graph decomposition and reconstruction strategies further simplifies the skeleton extraction task into a graph component detection problem, which significantly improves the accuracy and robustness of extracted skeletons. (2) The intuitive representation of each skeleton branch with multiple structured and overlapping line segments can effectively prevent the skeleton branch vanishing problem. (3) In comparison to traditional skeleton heatmaps, our approach directly outputs skeleton graphs, which is more feasible for real-world applications. Through comprehensive experiments, we demonstrate the advantages of BlumNet: significantly higher accuracy than the state-of-the-art AdaLSN (0.826 vs. 0.786) on the SK1491 dataset, a marked improvement in robustness on mixed object deformations, and also a state-of-the-art performance on binary shape datasets (e.g. 0.893 on the MPEG7 dataset).
-
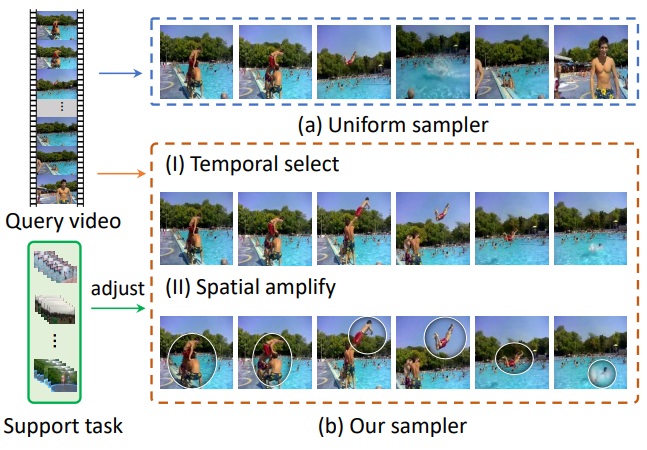 ×Task-adaptive spatial-temporal video sampler for few-shot action recognitionHuabin Liu, Weixian Lv, John See, and Weiyao LinProceedings of the 30th ACM International Conference on Multimedia, 2022
×Task-adaptive spatial-temporal video sampler for few-shot action recognitionHuabin Liu, Weixian Lv, John See, and Weiyao LinProceedings of the 30th ACM International Conference on Multimedia, 2022A primary challenge faced in few-shot action recognition is inadequate video data for training. To address this issue, current methods in this field mainly focus on devising algorithms at the feature level while little attention is paid to processing input video data. Moreover, existing frame sampling strategies may omit critical action information in temporal and spatial dimensions, which further impacts video utilization efficiency. In this paper, we propose a novel video frame sampler for few-shot action recognition to address this issue, where task-specific spatial-temporal frame sampling is achieved via a temporal selector (TS) and a spatial amplifier (SA). Specifically, our sampler first scans the whole video at a small computational cost to obtain a global perception of video frames. The TS plays its role in selecting top-T frames that contribute most significantly and subsequently. The SA emphasizes the discriminative information of each frame by amplifying critical regions with the guidance of saliency maps. We further adopt task-adaptive learning to dynamically adjust the sampling strategy according to the episode task at hand. Both the implementations of TS and SA are differentiable for end-to-end optimization, facilitating seamless integration of our proposed sampler with most few-shot action recognition methods. Extensive experiments show a significant boost in the performances on various benchmarks including long-term videos.
-
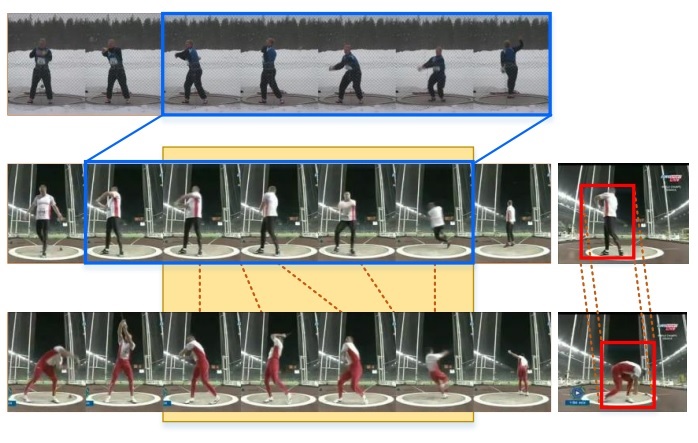 ×Ta2n: Two-stage action alignment network for few-shot action recognitionShuyuan Li, Huabin Liu, Rui Qian, Yuxi Li, John See, Mengjuan Fei, Xiaoyuan Yu, and Weiyao LinProceedings of the AAAI Conference on Artificial Intelligence, 2022
×Ta2n: Two-stage action alignment network for few-shot action recognitionShuyuan Li, Huabin Liu, Rui Qian, Yuxi Li, John See, Mengjuan Fei, Xiaoyuan Yu, and Weiyao LinProceedings of the AAAI Conference on Artificial Intelligence, 2022Few-shot action recognition aims to recognize novel action classes (query) using just a few samples (support). The majority of current approaches follow the metric learning paradigm, which learns to compare the similarity between videos. Recently, it has been observed that directly measuring this similarity is not ideal since different action instances may show distinctive temporal distribution, resulting in severe misalignment issues across query and support videos. In this paper, we arrest this problem from two distinct aspects–action duration misalignment and action evolution misalignment. We address them sequentially through a Two-stage Action Alignment Network (TA2N). The first stage locates the action by learning a temporal affine transform, which warps each video feature to its action duration while dismissing the action-irrelevant feature (eg background). Next, the second stage coordinates query feature to match the spatial-temporal action evolution of support by performing temporally rearrange and spatially offset prediction. Extensive experiments on benchmark datasets show the potential of the proposed method in achieving state-of-the-art performance for few-shot action recognition.
-
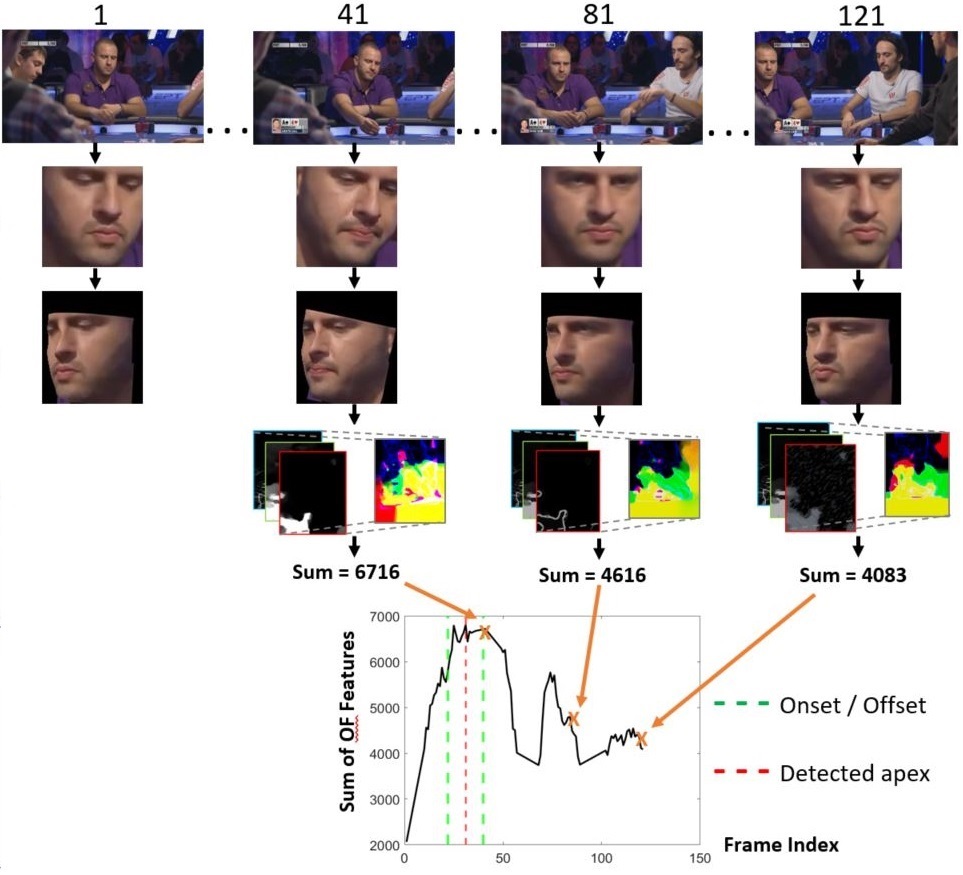 ×Needle in a Haystack: Spotting and recognising micro-expressions “in the wild”Y.S. Gan, John See, Huai-Qian Khor, Kun-Hong Liu, and Sze-Teng LiongNeurocomputing, 2022
×Needle in a Haystack: Spotting and recognising micro-expressions “in the wild”Y.S. Gan, John See, Huai-Qian Khor, Kun-Hong Liu, and Sze-Teng LiongNeurocomputing, 2022Computational research on facial micro-expressions has long focused on videos captured under constrained laboratory conditions due to the challenging elicitation process and limited samples that are publicly available. Moreover, processing micro-expressions is extremely challenging under unconstrained scenarios. This paper introduces, for the first time, a completely automatic micro-expression “spot-and-recognize” framework that is performed on in-the-wild videos, such as in poker games and political interviews. The proposed method first spots the apex frame from a video by handling head movements and unconscious actions which are typically larger in motion intensity, with alignment employed to enforce a canonical face pose. Optical flow guided features play a central role in our method: they can robustly identify the location of the apex frame, and are used to learn a shallow neural network model for emotion classification. Experimental results demonstrate the feasibility of the proposed methodology, establishing good baselines for both spotting and recognition tasks – ASR of 0.33 and F1-score of 0.6758 respectively on the MEVIEW micro-expression database. In addition, we present comprehensive qualitative and quantitative analyses to further show the effectiveness of the proposed framework, with new suggestion for an appropriate evaluation protocol. In a nutshell, this paper provides a new benchmark for apex spotting and emotion recognition in an in-the-wild setting.
-
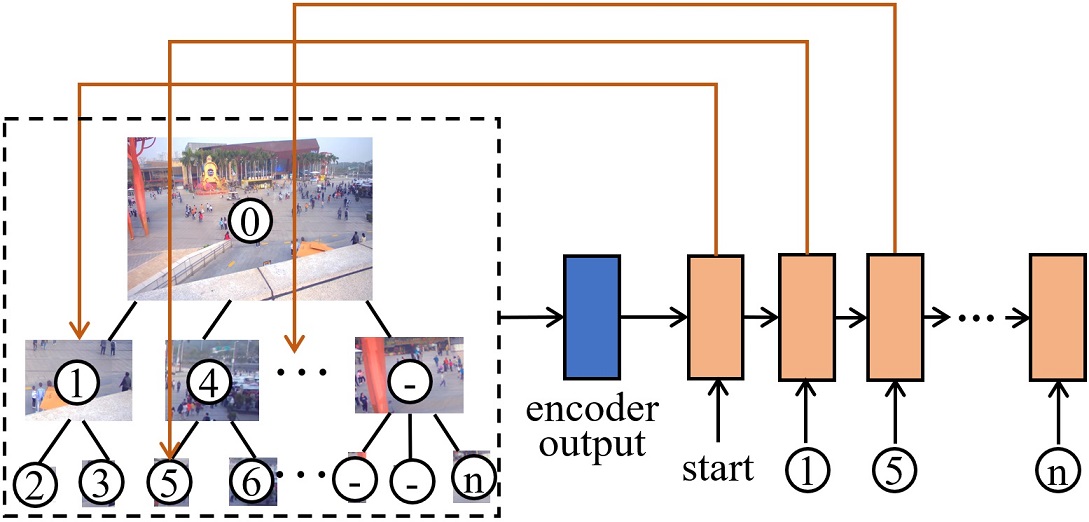 ×Speed up object detection on gigapixel-level images with patch arrangementJiahao Fan, Huabin Liu, Wenjie Yang, John See, Aixin Zhang, and Weiyao LinProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022
×Speed up object detection on gigapixel-level images with patch arrangementJiahao Fan, Huabin Liu, Wenjie Yang, John See, Aixin Zhang, and Weiyao LinProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022With the appearance of super high-resolution (e.g., gigapixel-level) images, performing efficient object detection on such images becomes an important issue. Most existing works for efficient object detection on high-resolution images focus on generating local patches where objects may exist, and then every patch is detected independently. However, when the image resolution reaches gigapixel-level, they will suffer from a huge time cost for detecting numerous patches. Different from them, we devise a novel patch arrangement framework for fast object detection on gigapixel-level images. Under this framework, a Patch Arrangement Network (PAN) is proposed to accelerate the detection by determining which patches could be packed together into a compact canvas. Specifically, PAN consists of (1) a Patch Filter Module (PFM) (2) a Patch Packing Module (PPM). PFM filters patch candidates by learning to select patches between two granularities. Subsequently, from the remaining patches, PPM determines how to pack these patches together into a smaller number of canvases. Meanwhile, it generates an ideal layout of patches on canvas. These canvases are fed to the detector to get final results. Experiments show that our method could improve the inference speed on gigapixel-level images by 5 times while maintaining great performance.